LOPs SideCar Server
The LOPS SideCar Server is a separate backend application designed to handle computationally intensive tasks, particularly those involving heavier vision tasks like Florence-2 and OCR engines (EasyOCR/PaddleOCR).
- Offloading Computation: It runs heavy model inference in a separate process, preventing the main TouchDesigner process from freezing or becoming unresponsive.
- Resource Management: It allows demanding models to run on potentially different hardware (though currently designed for localhost) or simply utilize system resources (CPU, GPU, RAM) more effectively without impacting TouchDesigner’s real-time performance.
Think of it as a dedicated helper application that specific LOPS operators communicate with to get complex jobs done.
How it Works
Section titled “How it Works”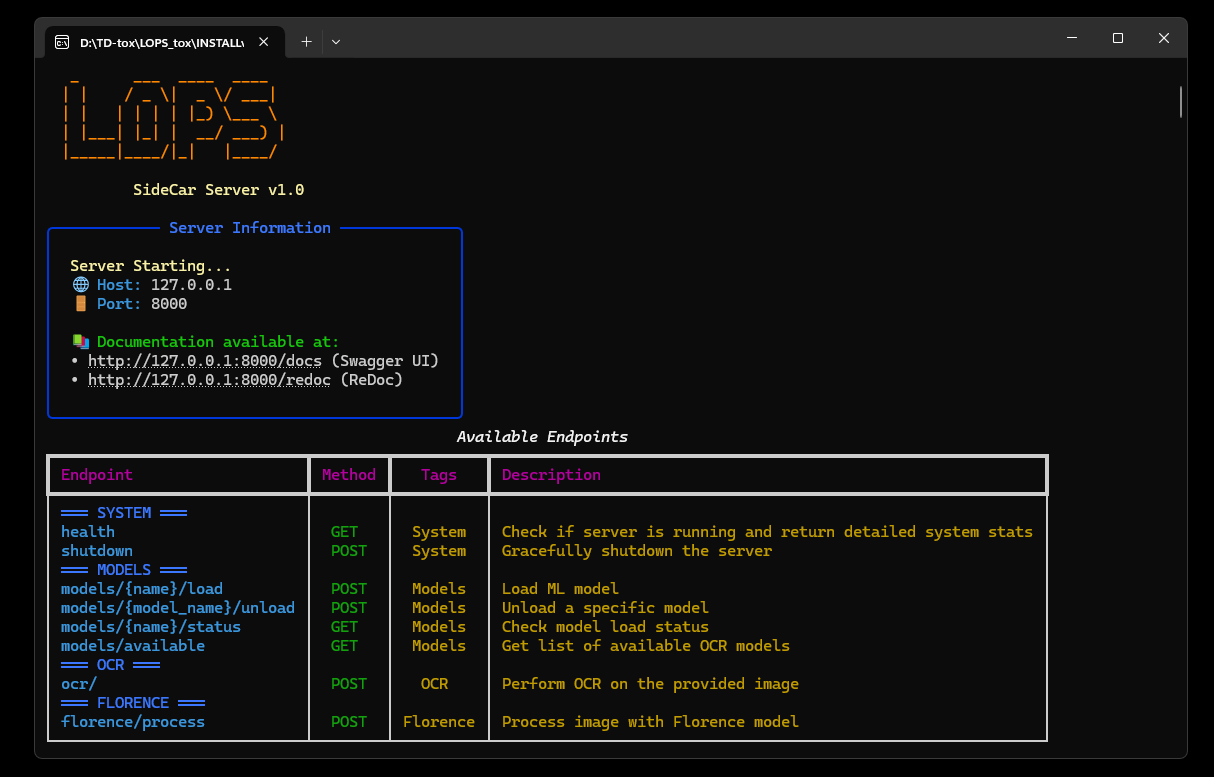
When you use an operator like Florence or OCR, it doesn’t run the ML model directly within TouchDesigner. Instead, it sends a request to the SideCar server:
- Request: The LOP (e.g.,
Florence) packages the necessary data (like an image and task parameters) and sends it to the SideCar server via a local HTTP request (typically tohttp://127.0.0.1:8000). - Processing: The SideCar server receives the request, loads the required ML model (if not already loaded), performs the inference (e.g., image captioning, OCR), and prepares the results.
- Response: The SideCar server sends the results back to the requesting LOP in TouchDesigner.
- Update: The LOP receives the results and updates its output DATs or parameters.
The SideCar Operator
Section titled “The SideCar Operator”Located within the main LOPS component (op('dot_lops/SideCar')), this operator manages the SideCar server process itself.
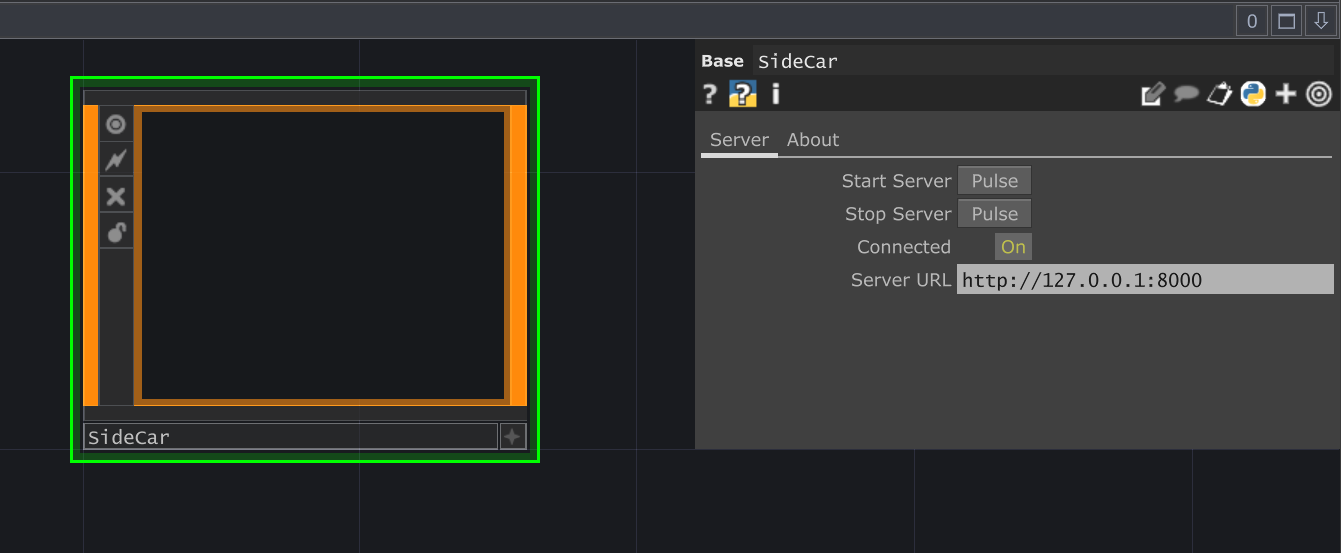
Key features managed by this operator:
- Auto-Launch: If an operator like
FlorenceorOCRtries to send a request and the SideCar server isn’t running, theSideCaroperator will automatically attempt to launch thesidecar_server.pyscript in its configured Python virtual environment. A separate command window will typically appear showing the server’s startup logs. - Task Queuing: If requests are sent while the server is starting up or temporarily unavailable, the
SideCaroperator queues these requests. Once the server is confirmed to be connected (via its/healthendpoint), the queued tasks are sent for processing. - Connection Status: The
Connectedparameter on theSideCaroperator indicates whether it can successfully communicate with the backend server.
Interaction Model
Section titled “Interaction Model”For the most part, users interact with the SideCar indirectly. You use the parameters on operators like Florence or OCR (e.g., pulsing Process, selecting models), and those operators handle the communication with the SideCar service automatically.
Setup & Dependencies
Section titled “Setup & Dependencies”The SideCar server runs within the Python virtual environment specified in the main ChatTD operator’s settings (Python Venv parameter).
Crucially, this virtual environment must have the necessary dependencies installed for the models you intend to use.
Common dependencies needed by the SideCar server include:
fastapi: The web framework for the server.uvicorn: The ASGI server to run FastAPI.requests: For internal communication (though less relevant for dependencies).python-multipart: For handling file uploads if needed in the future.numpy,opencv-python-headless,Pillow: Image processing.rich: For formatted console output in the server window.psutil: For system monitoring.pynvml: (Optional, for GPU monitoring on NVIDIA hardware).
Model-Specific Dependencies:
- Florence-2:
torch>=2.1.1,transformers,timm,einops. - OCR (EasyOCR):
easyocr(which includestorchand others). - OCR (PaddleOCR):
paddleocr,paddlepaddle-gpu(orpaddlepaddle).
You can install these using the ChatTD Python Manager. Make sure you are targeting the correct virtual environment selected in the main ChatTD operator.
Starting & Stopping the Server
Section titled “Starting & Stopping the Server”- Automatic: As mentioned, the server typically starts automatically when needed by a dependent operator (
Florence,OCR). - Manual Start: You can pulse the
Start Serverparameter on theSideCaroperator (op('dot_lops/SideCar')) to manually launch it. - Manual Stop: Pulsing
Stop Serversends a shutdown request (/shutdown) to the server process, asking it to exit gracefully. Closing the command window that pops up when the server starts is often the most direct way to ensure it stops.
Monitoring & API Docs
Section titled “Monitoring & API Docs”- Stats Table: The
SideCaroperator contains an internalstats_tableDAT that provides real-time monitoring of the server’s status, system resource usage (CPU, RAM, GPU if detected), loaded models, and request statistics. - Command Window: The console window launched with the server displays live logs, including model loading, request processing, and any errors.
- API Documentation: The SideCar server uses FastAPI, which automatically generates interactive API documentation. If the server is running, you can access it in your web browser:
- Swagger UI: http://127.0.0.1:8000/docs
- ReDoc: http://127.0.0.1:8000/redoc
Related Operators
Section titled “Related Operators”Operators currently utilizing the SideCar service:
This guide provides an overview for users interested in the backend mechanics. For most use cases, interacting directly with the Florence or OCR operators is sufficient.