Florence-2 Operator
Overview
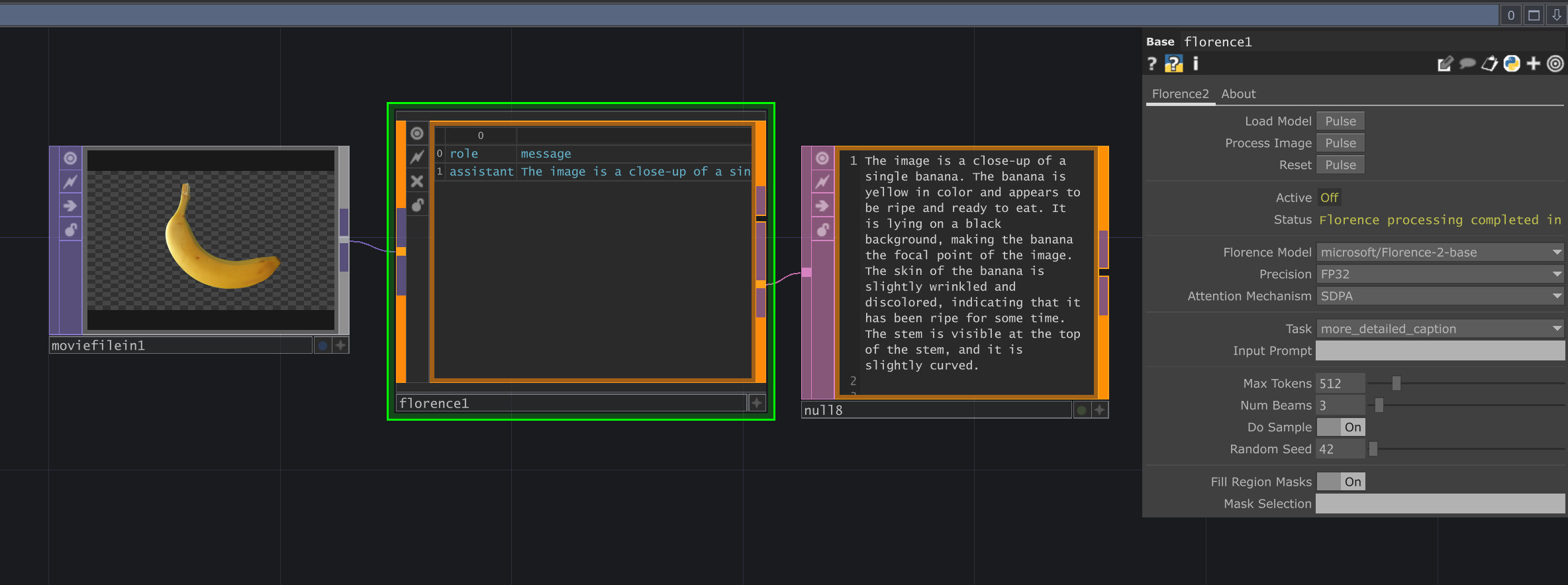
Section titled “Overview”The Florence-2 LOP provides an interface to Microsoft’s powerful Florence-2 vision foundation model. It enables a wide range of vision tasks, including detailed image captioning, object detection (region proposal), OCR (Optical Character Recognition), referring expression segmentation, and more. This operator requires the separate SideCar server to be running, as the actual model loading and inference computation happen within the SideCar process, utilizing its resources (potentially including a dedicated GPU).
Requirements
Section titled “Requirements”- SideCar Server: The SideCar server application must be running. See the SideCar Guide for setup instructions.
- SideCar Dependencies: The Python environment used by the SideCar server needs the following packages installed:
torch>=2.1.1(CUDA version recommended)transformerstimmeinops
- ChatTD Operator: Required for asynchronous communication with the SideCar server and logging. Ensure the
ChatTD Operatorparameter on the ‘About’ page points to your configured ChatTD instance.
Input/Output
Section titled “Input/Output”Inputs
Section titled “Inputs”- Input TOP (
in_top): Connect the image (TOP) you want to process here.
Outputs
Section titled “Outputs”- Output Text DAT (
output_dat): Contains the primary text result from the selected Florence-2 task (e.g., the generated caption, the OCR text). - Conversation DAT (
conversation_dat): Stores the latest interaction, typically including the input prompt (if used) and the assistant’s (Florence-2’s) response. - History DAT (
history_dat): Appends a log entry for each successful processing task, storing the role, message, model used, and timestamp.
Parameters
Section titled “Parameters”Page: Florence2
Section titled “Page: Florence2”op('florence').par.Load Pulse - Default:
None
op('florence').par.Process Pulse - Default:
None
op('florence').par.Reset Pulse - Default:
None
op('florence').par.Active Toggle - Default:
false
op('florence').par.Status String - Default:
None
op('florence').par.Prompt String - Default:
None
op('florence').par.Maxtokens Int - Default:
512
op('florence').par.Numbeams Int - Default:
3
op('florence').par.Dosample Toggle - Default:
true
op('florence').par.Seed Int - Default:
42
op('florence').par.Fillmask Toggle - Default:
true
op('florence').par.Maskselect Str - Default:
None
Page: About
Section titled “Page: About”op('florence').par.Bypass Toggle - Default:
false
op('florence').par.Showbuiltin Toggle - Default:
false
op('florence').par.Version String - Default:
None
op('florence').par.Lastupdated String - Default:
None
op('florence').par.Creator String - Default:
None
op('florence').par.Website String - Default:
None
op('florence').par.Chattd OP - Default:
None
Usage Examples
Section titled “Usage Examples”Image Captioning
Section titled “Image Captioning”1. Ensure the SideCar server is running.2. Connect an image TOP to the Florence-2 input.3. Select a desired model (e.g., 'microsoft/Florence-2-large') from the `Florence Model` menu.4. Pulse the `Load Model` parameter and wait for the status to indicate readiness (may take time on first load).5. Set the `Task` parameter to 'more_detailed_caption'.6. Pulse the `Process Image` parameter.7. Monitor the `Status` parameter. The generated caption will appear in the `output_dat` DAT.Optical Character Recognition (OCR)
Section titled “Optical Character Recognition (OCR)”1. Ensure SideCar is running and the desired model is loaded (pulse `Load Model`).2. Connect an image TOP containing text to the input.3. Set the `Task` parameter to 'ocr'.4. Pulse `Process Image`.5. The extracted text will appear in the `output_dat` DAT.Object Detection (Region Proposal)
Section titled “Object Detection (Region Proposal)”1. Ensure SideCar is running and the model is loaded.2. Connect an image TOP.3. Set the `Task` parameter to 'region_proposal'.4. Pulse `Process Image`.5. The results (bounding boxes and labels) will appear in the `output_dat` DAT (often as structured text or JSON). Visualizations may appear in the node viewer depending on internal settings.Technical Notes
Section titled “Technical Notes”- SideCar Dependency: This operator is critically dependent on the SideCar server. All model loading and inference occur in the SideCar process.
- Resource Intensive: Florence-2 models, especially the larger variants, require significant computational resources, primarily GPU VRAM. Ensure the machine running SideCar meets the requirements for the selected model.
- Asynchronous Operation: Communication with the SideCar server (loading models, processing images) is handled asynchronously via ChatTD’s TDAsyncIO, preventing TouchDesigner from freezing.
- Task-Specific Prompts: Some tasks like
docvqaorreferring_expression_segmentationrequire an appropriateInput Promptto function correctly. - Precision & Attention:
PrecisionandAttention Mechanismparameters affect performance and resource usage on the SideCar server.fp16/bf16andflash_attention_2(if installed and supported) can offer significant speedups.
Related Operators
Section titled “Related Operators”- SideCar: The backend service required for this operator to function.
- ChatTD: Provides core services like asynchronous task execution and logging.
- OCR Operator: Another operator focused specifically on OCR, potentially using different backends (like EasyOCR or PaddleOCR via SideCar).
Research & Licensing
Microsoft Research
Microsoft Research is a leading technology research organization focused on advancing the state-of-the-art in computer science and software engineering. Their computer vision research group has produced breakthrough models in object detection, image understanding, and multimodal AI systems.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Florence-2 is a vision foundation model that advances unified representation learning for computer vision. It can handle a wide variety of vision tasks through a single model using prompt-based task specification, making it highly versatile for applications ranging from image captioning to object detection and OCR.
Technical Details
- Vision Transformer Architecture: Unified encoder-decoder framework
- Multi-task Training: Single model handles captioning, detection, OCR, and segmentation
- Prompt-based Interface: Task specification through natural language prompts
Research Impact
- Unified Vision AI: Single model replacing multiple specialized vision systems
- Comprehensive Evaluation: Extensive benchmarking across diverse vision tasks
- Open Research: Democratizing access to advanced vision foundation models
Citation
@article{xiao2023florence,
title={Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks},
author={Xiao, Bin and Wu, Haiping and Xu, Weijian and Dai, Xiyang and Hu, Houdong and Lu, Yumao and Zeng, Michael and Liu, Ce and Yuan, Lu},
journal={arXiv preprint arXiv:2311.06242},
year={2023},
url={https://arxiv.org/abs/2311.06242}
} Key Research Contributions
- Unified vision foundation model for multiple tasks with prompt-based interface
- FLD-5B dataset with 5.4 billion comprehensive visual annotations
- State-of-the-art performance across diverse vision tasks including captioning, detection, and segmentation
License
MIT License - This model is freely available for research and commercial use.